반응형
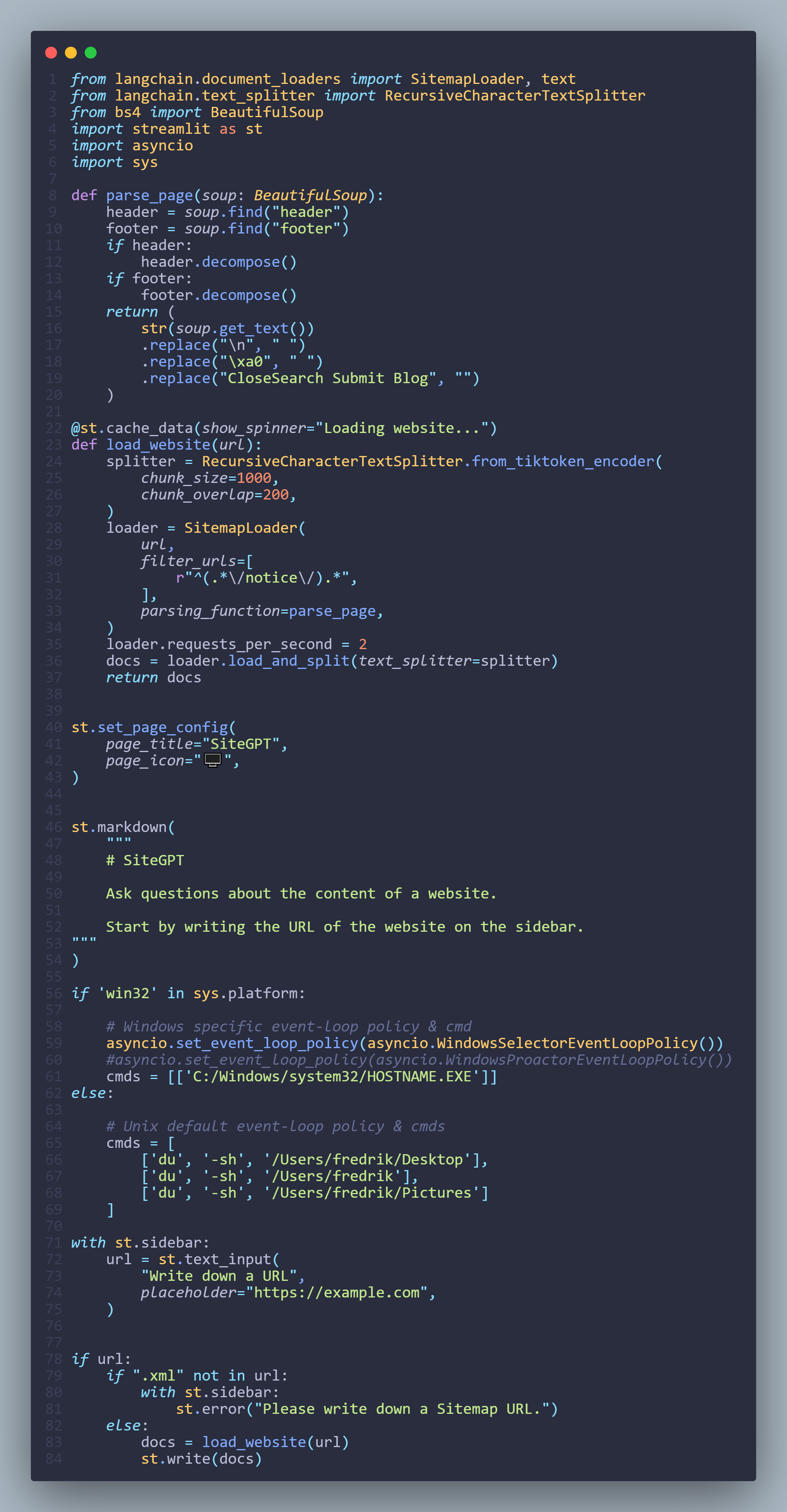
from langchain.document_loaders import SitemapLoader, text
from langchain.text_splitter import RecursiveCharacterTextSplitter
from bs4 import BeautifulSoup
import streamlit as st
import asyncio
import sys
def parse_page(soup: BeautifulSoup):
header = soup.find("header")
footer = soup.find("footer")
if header:
header.decompose()
if footer:
footer.decompose()
return (
str(soup.get_text())
.replace("\n", " ")
.replace("\xa0", " ")
.replace("CloseSearch Submit Blog", "")
)
@st.cache_data(show_spinner="Loading website...")
def load_website(url):
splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000,
chunk_overlap=200,
)
loader = SitemapLoader(
url,
filter_urls=[
r"^(.*\/notice\/).*",
],
parsing_function=parse_page,
)
loader.requests_per_second = 2
docs = loader.load_and_split(text_splitter=splitter)
return docs
st.set_page_config(
page_title="SiteGPT",
page_icon="🖥️",
)
st.markdown(
"""
# SiteGPT
Ask questions about the content of a website.
Start by writing the URL of the website on the sidebar.
"""
)
if 'win32' in sys.platform:
# Windows specific event-loop policy & cmd
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
#asyncio.set_event_loop_policy(asyncio.WindowsProactorEventLoopPolicy())
cmds = [['C:/Windows/system32/HOSTNAME.EXE']]
else:
# Unix default event-loop policy & cmds
cmds = [
['du', '-sh', '/Users/fredrik/Desktop'],
['du', '-sh', '/Users/fredrik'],
['du', '-sh', '/Users/fredrik/Pictures']
]
with st.sidebar:
url = st.text_input(
"Write down a URL",
)
if url:
if ".xml" not in url:
with st.sidebar:
st.error("Please write down a Sitemap URL.")
else:
docs = load_website(url)
st.write(docs)
사이트맵에서 가져온 정보에 대해 구문을 분석함
beautifulsoup을 이용하여 처리
Beautifulsoup.Tag.decompose()
Tag.decompose()는 주어진 HTML 문서의 트리에서 태그를 제거한 다음 태그와 그 내용을 제거
find()
HTML 문서에서 해당 태그 하나를 가져옴
get_text()
해당구문의 텍스트를 가져옴
'python' 카테고리의 다른 글
| [GPT][MEETINGGPT] Audio Extraction (0) | 2024.05.14 |
|---|---|
| [GPT][SITEGPT] Map Re Rank Chain (0) | 2024.05.13 |
| [GPT][SITEGPT] SitemapLoader (0) | 2024.05.13 |
| [GPT][SITEGPT] AsyncChromiumLoader (0) | 2024.05.02 |
| [GPT][QUIZGPT]Output Parser 를 이용한 데이터 형태 제어 (1) | 2024.04.18 |